As a developer you’re constantly working with large amounts of text like source code, logs, and data files. Often you need to extract, replace, or manipulate that text and regex can help you.
Today I present variants of a real case study where I personally used regex. These examples build upon my last post so check that out too.
This is a snippet of this csv file which you can also play with here.
reddit_id,colorblind_comment,score,title,url,created
...
8cwcbu,False,101457,"Cause of Death - Reality vs. Google vs. Media [OC]",https://i.imgur.com/GtIzEok.gif,1523970172
8bzdr8,False,99626,"Gaze and foot placement when walking over rough terrain (article link in comments) [OC]",https://v.redd.it/h0f0m4v5nor01,1523628194
fpga3f,False,99488,"[OC] To show just how insane this week's unemployment numbers are, I animated initial unemployment insurance claims from 1967 until now. These numbers are just astonishing.",https://i.redd.it/tch0t0is32p41.gif,1585245693
i2vx78,True,98638,"The environmental impact of Beyond Meat and a beef patty [OC]",https://i.redd.it/jskjkodg3se51.png,1596456703
fxoxti,False,98067,"Coronavirus Deaths vs Other Epidemics From Day of First Death (Since 2000) [OC]",https://v.redd.it/yemjrb1p9rr41,1586422082
...
(Top 100 posts from r/dataisbeautiful on Reddit where 'colorblind' is mentioned in the comments)
There are a ton of things you could extract here but I’ll go with this:
Extract image urls from posts with colorblind comments
You could use excel or write a script here but this is why I would use regex:
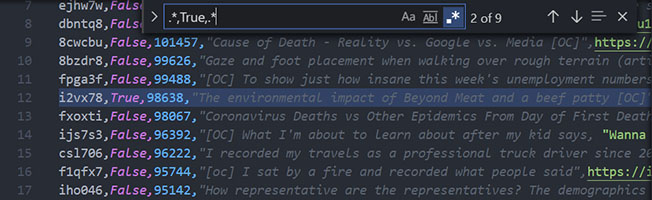
Step #1: Select all lines where the colorblind column is True
.*,True,.*
True match the word ‘True’, match commas (so we don’t match ‘True’ in the title text).* match everything before and afterStep #2: Limit to lines that have an image url
.*,True,.*http.*\.(png|jpg).*
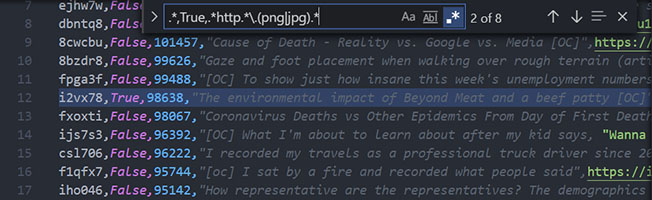
http.* match start of url (not necessary but needed for the next step)\.(png|jpg) match .png or .jpg extensionshttp.*\.(png|jpg) combine to match urls with an image extension.*,True,.* + http.*\.(png|jpg) + .* combine step 1 regex, the image url, and everything after. Now it matches lines with colorblind comments AND image urlsStep #3: Match just the url:
(?<=.*,True,.*,)http.*\.(png|jpg)(?=.*)
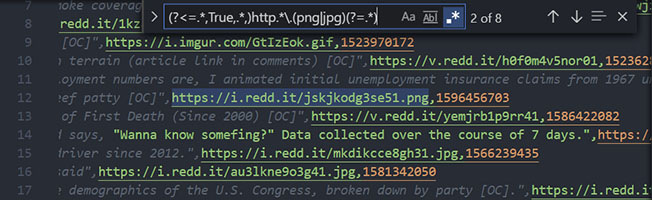
Lets break up our regex so far into parts:
part_1 |
Before the url | .*,True,.* |
part_2 |
The url | http.*\.(png|jpg) |
part_3 |
After the url | .* |
We want to isolate part_2 so must exclude part_1 and part_3 like this:
(?<= ... ) ... exclude stuff before a match... (?= ... ) exclude stuff after a match(?<= part_1 ) + part_2 + (?= part_3 ) exclude part_1 and part_3(?<=.*,True,.*)http.*\.(png|jpg)(?=.*) substitute in our actual regexStep #4: Extract the text
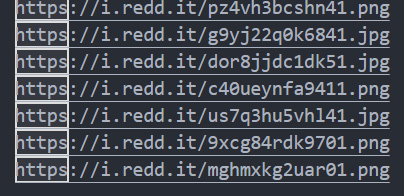
A modern IDE should now let you select your matches. In VS Code you can select and copy your matches like this:
Alt + Enter to select matchesCtrl + c to copy matchesCtrl + v to paste matches (in a separate file)Urls successfully extracted! You could take this further by running this over your entire repo using global search (Alt + Shift + f). Show me an excel script that does that!
Sometimes we don’t want to extract text but rather update it. For this example we’ll update all image urls in the file like so:
https://i.redd.it/jskjkodg3se51.pnghttps://i.redd.it/png/jskjkodg3se51Step #1: Match image urls (with ID match)
http.*/.*\.(png|jpg)
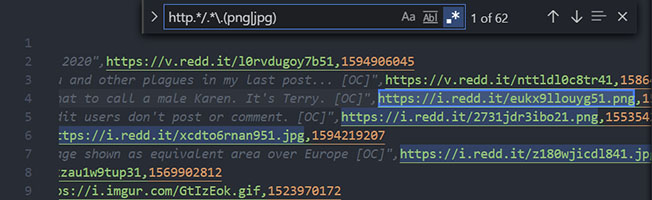
http.* match start of url and everything after/.* match forward slash and everything after (matches the image ID)\.(png|jpg) match .png or .jpg extensionsStep #2: Create regex groups
(http.*)/(.*)\.(png|jpg)
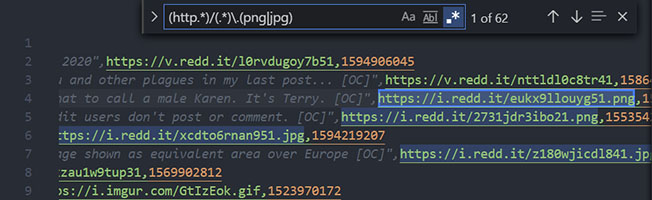
Everything wrapped with () creates a regex group which we can reference in our replace command.
Given the url https://i.redd.it/jskjkodg3se51.png we must create groups for the following parts to transform them as desired:
https://i.redd.it/ the domain partjskjkodg3se51 the image ID partpng the image extension partLet’s group those parts of our regex:
(http.*) groups the domain part/(.*) groups the image ID part (note the slash is excluded)\.(png|jpg) groups the image extension part (note this was already grouped and that . is excluded)Step #3: Replace
(http.*)/(.*)\.(png|jpg) + $1/$3/$2
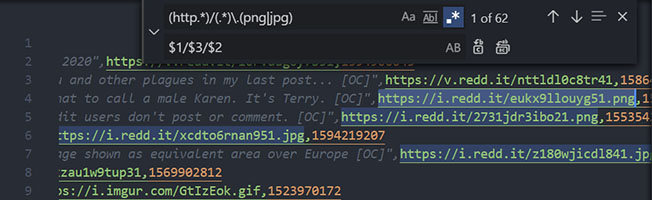
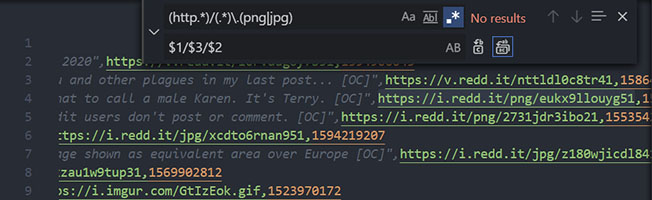
Open the replace UI (Ctrl + h in most IDEs)
We can now reference groups in replace commands as follows:
$0 is the entire match$1, $2, $3 is the first, second, third group etcOur search and replace commands will therefore look like this:
(http.*)/(.*)\.(png|jpg)$1/$3/$2That regex replace will change urls like so:
https://i.redd.it/jskjkodg3se51.png -> https://i.redd.it/png/jskjkodg3se51https://i.redd.it/mkdikcce8gh31.jpg -> https://i.redd.it/jpg/mkdikcce8gh31Nice huh? You can also do this globally via Alt + shift + h to search and replace over your whole repo. Very useful.
Powerful stuff eh? Once you learn how to build up a regex like this (hint: practice makes perfect) you can do this kind of stuff in seconds. Searching, extracting, and transforming text will become second nature.
Well that’s it for now! I’ve got 2 more sections of this case study ready to go but this article was getting long. So next week we’ll learn how to use multi-cursors to augment regex even further.
It’s seriously powerful stuff! Until then 👋